In
The Decline of Deviance, I argued that:
Many forms of risk-taking and rule-breaking have declined since the 1990s.
This is both good (less crime) and bad (less innovation).
Deviance is declining because prosperity has increased—people have more to lose, and they’re acting like it.
Since I put it out last October, this has become my most-read post of all time. Lots of folks have chimed in with hypotheses, critiques, and good old-fashioned internet dunks, so let’s see if we can take this idea one level deeper, and weave something out of all these loose threads.
That’s right: we’re doing a sequel to the post about how there are too many sequels.
THE KIDS STOPPED SMOKING AND NOBODY CARED
The most common response I got was: “how awful!”
(The trends, not the post itself, although that too sometimes.)
To most folks, the decline of deviance is a turn for the worst. Previous generations got to live through artistic golden ages, while we have to suffer through an era where there are four different movies that are all, technically,
Spider-Man 2.[...]
But this response misses half the post, and the most important point.
In 1995, half of high school students drank, 35% smoked, and 40% had at least tried weed. 10% of them had brought a weapon to school at some point. About 6% of girls aged 15-19 were pregnant. Crime rates were about as high as they had been since we started keeping track of them.
Over the next 30 years, all of these problems shrank and some of them nearly disappeared. And not because of anything we did on purpose! We have no idea how to get kids to stop smoking—when we try to persuade them,
we sometimes cause them to smoke more. No, these improvements happened basically by magic, for free, and—I think—as a byproduct of our increasing prosperity. This is like waking up one day to find that you’ve been left a large fortune by a long-lost aunt.
How does this great, unearned victory make us feel? Apparently, it doesn’t make us feel anything. We would have spent billions to solve all of these problems back in the 1990s—no doubt we were spending considerable sums of money on anti-drug programs and public service announcements, wasting almost all of it—and yet when we got the thing we wanted so badly, we didn’t even notice.
Now we’re on to worrying about whether the kids are too sad, whether they play outside enough, etc. Which is all reasonable and fine, but also, can we take a win? Can we at least try to reverse-engineer how some of these trendlines ended up going in our preferred directions, so we can make more of them do that?
I, too, would like to see a movie that is not
Spider-Man 2. But I also appreciate that I can watch it safely in my home without fear of being attacked by pregnant teenage criminals.
THE INTERNET DIDN’T DO ITMany people looked at the trends I presented and said, “Oh, the internet did this”. Maybe the internet killed the vibe by enabling mass surveillance—everyone’s afraid to be weird inside the digital panopticon, where all of your behaviors are recorded, uploaded, and permanently preserved. Or maybe the internet flattened culture by subjecting it to algorithmic curation. We can’t have nice things anymore because the computers won’t show them to us.
Both of these hypotheses are probably wrong, because the internet—at least, the internet as we know it today—simply showed up too late to be a plausible suspect. A majority of Americans didn’t get broadband until
2007. Instagram only launched in
2010, which was also the year that
iPhones got a front-facing camera. So the transition from the 1990s to the 2000s, where we see many forms of deviance declining, is not really the transition from “pre-internet” to “post-internet”. That transition happened somewhere around 2012 when
a majority of people got a smartphone, and long after most of these trends were already in motion.
So I don’t think the internet is the killer, but I do think it’s an accessory after the fact. In particular, I think the internet accelerated three trends that don’t get much attention. I’m going to call them
cultural carcinization, de-frictioning, and the flat-Earth problem.
1. CULTURAL CARCINIZATIONIn nature, apparently, being a crab is a good way to be. Several independent evolutionary lineages have ended up with crab-like body plans, a process called
carcinization.
Culture can carcinize too, not in the sense that we all turn into crabs, but in the sense that we converge on a small set of strategies. If you’ve ever played a “social deduction” or “hidden role” game like Werewolf, Mafia, The Resistance, Avalon, or Secret Hitler, you’ve seen this happen in real time. Things start out wild and unpredictable as people get a feel for the rules. But everyone’s tactics have to evolve because each gambit can only work once (“If you’re the Secret Hitler, raise your hand right now!”). If you play long enough with the same group, eventually you’ll end up with a handful of maneuvers that continue to be viable even after they’re known, often because they’re difficult to pull off. At this point, the game becomes both extremely competitive and extremely repetitive. This is what cultural carcinization looks like.
The faster we can communicate, the faster we culturally carcinize. When information only travels as fast as humans can walk or horses can run, it takes a long time for any given strategy to play itself out. As we acquire steamships, railroads, telephones, and airplanes, the pace of the game picks up, and tactics have to turn over faster and faster. By the time we get the internet, it’s like every human on Earth is playing Secret Hitler a million times a day. (Except some people are not-so-secretly Hitlers.) Strategies appear and go out of date almost instantaneously until we all end up in a
Nash equilibrium, where there’s no way for anyone to get the upper hand anymore.
The internet gives every social trend a pair of rocket-powered roller skates, speeding it toward its crablike final form. On Twitter, for instance, memes go from punchy to passé in a matter of days rather than decades. But if we could play culture on 1x speed rather than 10x speed, if we had time to screw around with different strategies before the game reached its cutthroat stage, we might have discovered different paths entirely. Maybe some folks would end up as crabs, while others became lobsters or kangaroos. Instead, in a hyper-competitive marketplace of ideas, we end up with the same few memes, all done to death.
2. DE-FRICTIONINGWe’ve forgotten how much time people in the past spent consuming content that they didn’t actually want to consume: the unskippable clunker of a song that came in the middle of an album, the late-night infomercial that you sat through because there was nothing else on, the magazine you read cover-to-cover in the waiting room because your doctor was 45 minutes late.
Each new media technology reduces this friction. CDs, TiVo, satellite radio, streaming—they all allow us to spend more time with the content that we supposedly desire. And what happens when this friction goes away? Well, in the mid-1990s, a pair of Russian artists named
Komar and Melamid surveyed people around the world about their artistic preferences, and then they painted the “most wanted” scene from each country. The results looked like this:
The lesson here is that when people can articulate exactly what they want, and when the marketplace can give it to them, most folks end up sucking down slop. But I don’t think this is because humans yearn for crap and kitsch. I think it’s because no one knows actually what they like until they’re confronted by it. If you cater to people’s raw, undeveloped preferences, sure, you’re going to take them to Sloptown. But people are capable of acquiring more interesting tastes, if you give them the chance. This is the work art does for us—it stretches our desires, rather than merely satisfying them. [...]
This is Komar and Melamid’s second lesson: if you want to see something interesting, you have to see things that you might dislike. And I don’t mean things that merely bore you, like an AI-written Netflix series that’s only meant to be half-watched while you also shop for shoes on your phone. I mean things that grab your attention, only to slap it around. Acquiring new tastes means, from time to time, spitting things out.
In a frictionless environment, however, this never has to happen. The internet excels at identifying what people already seem to want, and giving it to them good and hard. Oh, you liked that video where a monkey eats a piece of cantaloupe? How about 30 million more of those? How about an anteater licking a watermelon? Will that keep your attention for another three seconds? Wait, don’t go yet!! We’ve got a baby hedgehog nibbling on a pineapple!!
3. THE FLAT-EARTH PROBLEMPeople once
theorized that globalization would cause niche culture to thrive because small-timers could make their living by selling to a tiny proportion of the populace spread all over the globe—the so-called “long tail”. That did become
possible, but it didn’t become
desirable. Everybody came to the same realization: once you can reach anyone, why not try to reach everyone? Why sell to one thousand people in every single country, when you could sell to every single person in every single country?
Here’s the rub: the more customers you want, the more you have to cater to the lowest common denominator. If you want your film to play in every theater on earth, then it has to appeal to eight billion different sensibilities, which also means it’s going to suck. This is the
flat-Earth problem.
It’s easy to see these effects if you know where to look. Because Hollywood wants to sell movies in every market, they’re willing to do everything from
editing out laundry clotheslines that make a country look “too backward” to pretending that Freddie Mercury wasn’t gay. [...]
AM I JUST UNCOOL?While some folks blamed the internet for the decline of deviance, other people denied the decline entirely.
One common retort to my argument was that I’m just an old fuddy-duddy. For example, a blogger named Jenn
claims that I am too uncool and out of touch to understand the cultural innovation happening in new forms of media like YouTube and Roblox. “Before I take a ‘culture is stagnating’ take seriously,” Jenn writes, “I want to see proof of work by the critics.” She concludes: “The culture is fine. Go play
Return of the Obra Dinn.” (Return of the Obra Dinn is a video game.) [...]
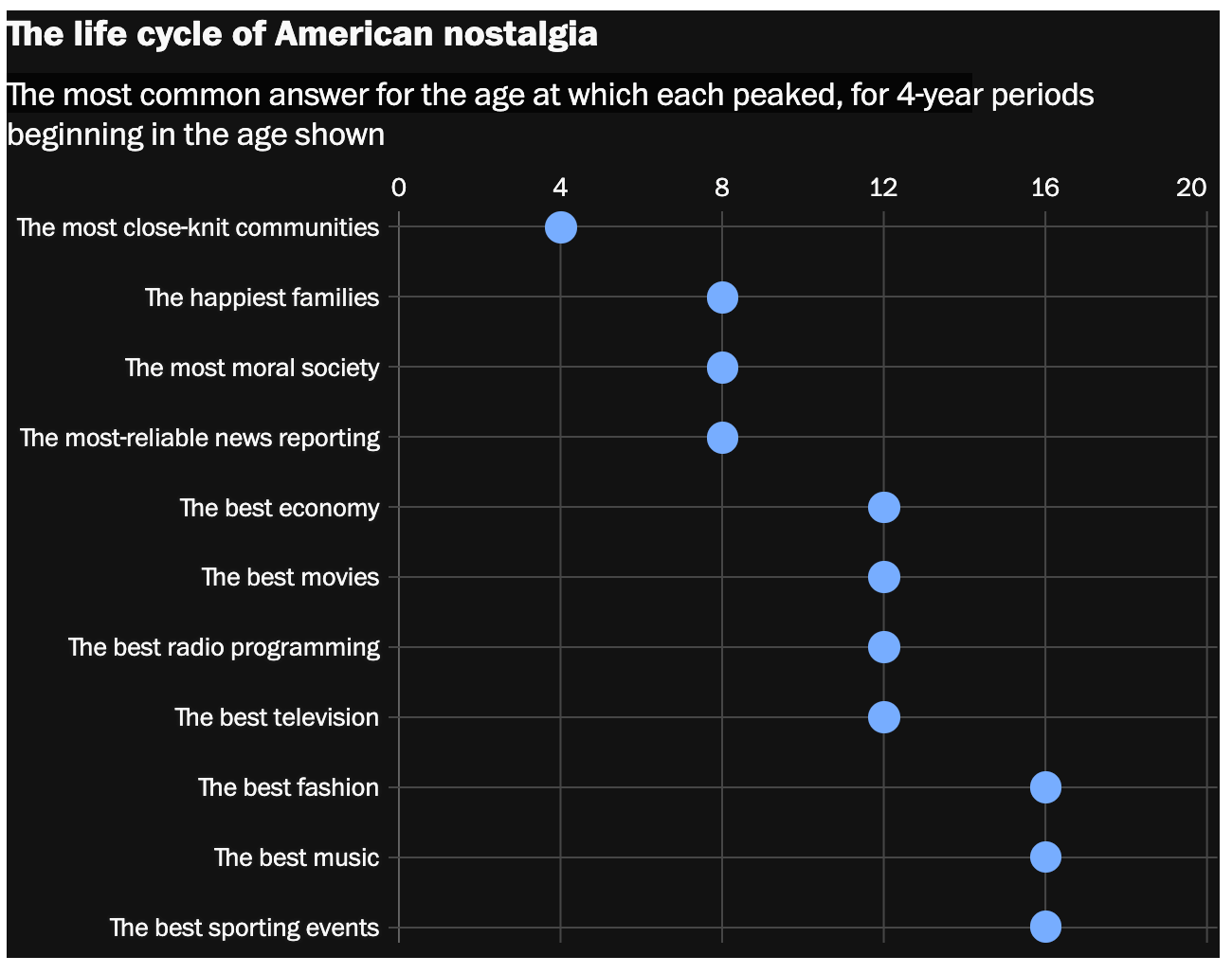
Pettiness aside, I think Jenn’s claim is plausible: the older you get, the less access you have to the most interesting parts of culture. If you think things are stagnating, you’re just admitting that you aren’t getting invited to the cool parties anymore. Plus, old folks can’t stop themselves from seeing the past through rose-colored glasses—in survey after survey, people think pretty much everything in culture just happened to peak when they were between four and twelve years old:
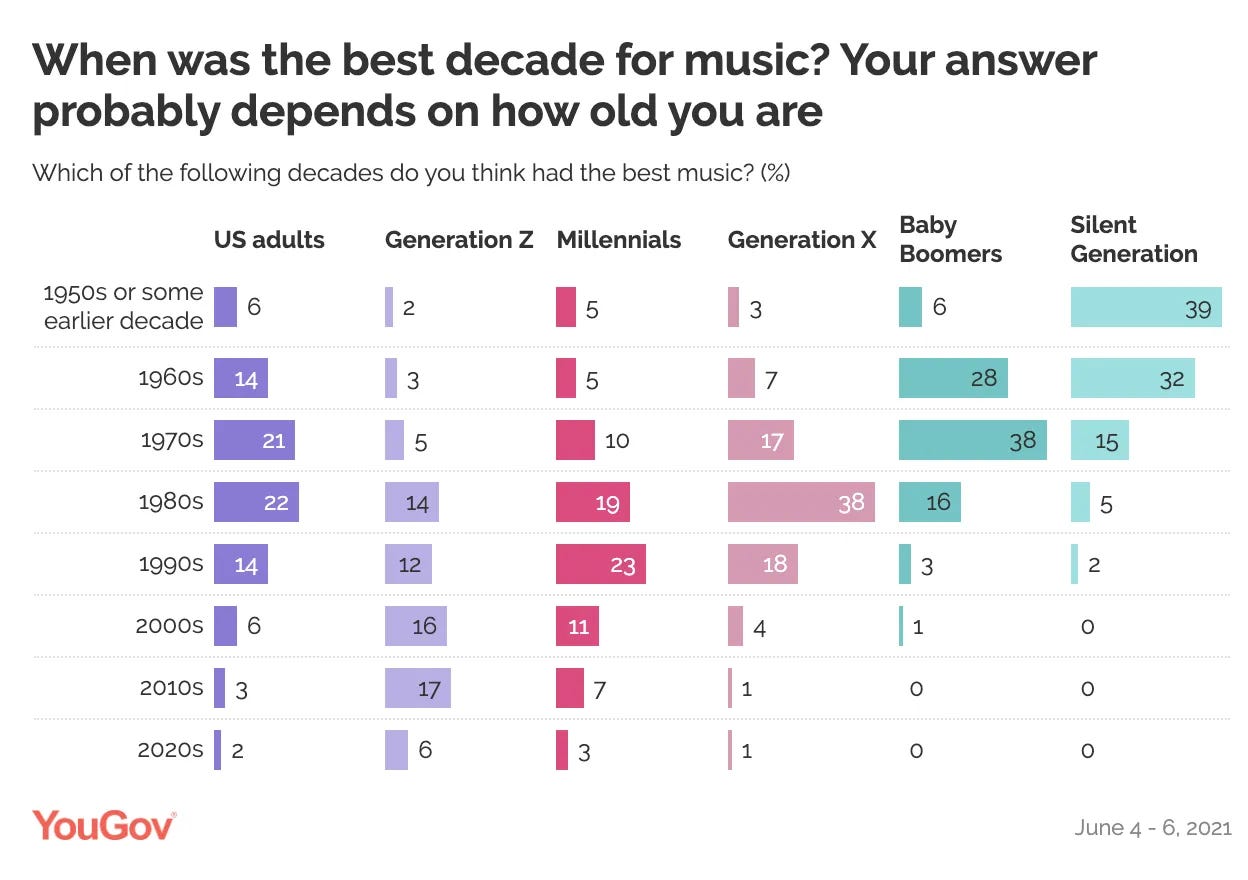
But things get a little more complicated when you separate people’s responses by age. When you first glance at this YouGov survey, it seems like every generation strongly prefers the music from their own childhood:
But look a little closer. The responses from Gen X, Baby Boomers, and the Silent Generation all have a clear peak flanked by much smaller hills. Millennials’ preferences, on the other hand, are more spread out. And Gen Z’s preferences are basically a plateau—they’re almost equally likely to nominate the 1980s, 1990s, 2000s, and 2010s.
We can’t know whether this is an age effect that they’ll grow out of—maybe every generation was culturally omnivorous when they were younger, and their tastes only calcified when they got older. But I doubt it. For all you Gen X’ers out there, did you spend your teenage years spinning your parents’ Perry Como records until you suddenly switched to Led Zeppelin in adulthood?
Besides, Jenn’s age argument cuts both ways. Old folks are biased by nostalgia, but young folks are biased by inexperience. When you’re young, everything seems new because it’s new to
you. You don’t know that your favorite anime is a rehash of a movie from the 1980s, because you weren’t alive in the 1980s. You’re not tired of the tropes yet because you’ve only seem them a few dozen times. You can’t pine for what you lost because you never had it in the first place.
It’s reasonable to be skeptical of any narrative of decline—I did my PhD on
why people perceive declines that haven’t actually happened. But (a), unlike most of those spurious nostalgic fantasies, the decline of deviance has both pros and cons. And (b), there are so many weird phenomena here and they need explaining, not just waving away.
For instance— [...]
NO MORE STRANGE BEDFELLOWS
Another theory that readers put forward: the deviance got scarce because life got hard. Nobody can do cool art anymore because everything is too expensive: housing, college, supplies, etc.
I think this is probably wrong. I suspect that it’s always been hard to be an artist, and previous generations were simply more willing to starve for it—not because they were braver, but because the difference between starving and not-starving used to be much smaller. [...]
You don’t have to go that far into the past to find a kind of poverty that feels foreign today. I read an article a while back about punk musicians living in New York in the 1970s, and they’re sleeping in roach-infested flophouses, they’re making music in abandoned buildings, they’re getting evicted and mugged and addicted to drugs.They’re truly broke, not “I can’t contribute to my retirement fund this month” broke, but “I might have to spend the night on this bench because I can’t afford a bus ticket back home” broke. I know plenty of aspiring musicians are out there slumming it right now, but this is a level of deprivation that most folks in developed countries would find unacceptable, if not downright dangerous. Once you’re sleeping rough, it’s time to hawk the guitar and call the temp agency.
That’s not because dire poverty became less glamorous—it was never glamorous!—but because it became
uncommon. When five musicians spend the night in a bus station, that’s called being punk. When one musician spends the night in a bus station, that’s called being homeless.
The richer the world gets, the higher the opportunity cost that starving artists have to pay. If you’ve got the chops to write a great novel, then you might also have the chops to make $95k working as a product manager for some mid-sized fintech firm. If your alternative was tilling turnips or spending six months at sea hunting sperm whales, you might say, screw it, I’d rather go hungry for my art than go somewhat less hungry for anything else. But that manuscript in your desk drawer is less enticing when you can have PTO and dental and an annual international vacation where you get to sleep in a bed that doesn’t have any strangers in it. [...]
As William James wrote
100 years ago:
We have grown literally afraid to be poor. We despise any one who elects to be poor in order to simplify and save his inner life. [...] We have lost the power even of imagining what the ancient idealization of poverty could have meant: the liberation from material attachments, the unbribed soul, the manlier indifference, the paying our way by what we are or do and not by what we have, the right to fling away our life at any moment irresponsibly,—the more athletic trim, in short, the moral fighting shape.
The difference is that today we don’t despise people who
elect to be poor, I think, because we don’t know any of them.
THE DECLINE OF DEVIANCE, THE RISE OF TOLERANCE
Many people asked some version of, “Is the decline of deviance actually an increase in tolerance?” After all, even if you wanted to be deviant today, how would you do it? [...]
So no doubt part of the decline of deviance is an increase in tolerance. But I think it, too, can be explained by the rise of mass prosperity.
The economists Daron Acemoglu and James Robinson
argue that nations get rich when they build inclusive economic and political institutions. Oligarchs and aristocrats fear any growth or reform that they can’t control, which in practice means basically
all growth and reform. (“We do not desire at all that the great masses shall become well off and independent,” once
remarked Frederick Gantz, an imperial flunky of Francis I of Austria. “How could we otherwise rule over them?”) If the plebs and the serfs can get a bit of money and power, however, it kicks off a virtuous cycle. Once people have some cash and influence, it becomes bad business and bad politics to shut them out—if you won’t engage with them, someone else will, and your more open-minded rivals will eventually out-compete you.
This process takes a long time, it’s uneven, and it’s not close to being completed. However, a few generations of semi-inclusive institutions have created a much wider spectrum of acceptable lifestyles. If you want to live in a polyamorous, genderless vegan witch commune, you can order your nutritional yeast on Amazon, trade memes with your friends on Tumblr, and vote for Democrats who think your choices are a-ok. If you want to live in a neoreactionary monarchist compound where you stockpile weapons and hunt bears, you can buy your guns at Wal-Mart, read posts on TruthSocial, and vote for Republicans who are on board with all of it. As long as you have money to spend and ballots to cast, someone can get ahead by catering to you.
(Case in point: one of the “platinum sponsors” of the New York City Pride Parade is
Deutsche Bank.)
This is a good thing. Inclusive institutions make everybody better off, except for the few cleptocrats who used to live in palaces while everyone else lived in shacks.
The downside is that every corner of culture gets commercialized. Reading comic books, listening to death metal, piercing body parts other than your ears—these used to be legitimately countercultural acts that distanced you from polite society and bonded you to an alternative community. Now you can do all these things at the mall. The Hot Topic-ization of culture means that anything new and interesting gets co-opted and mass-produced, thus draining it of everything that made it cool in the first place.
by Adam Mastroianni, Experimental History |
Read more:
Images: Mr. Mastrioianni; Joanna M. Wolfe; YouGov/WaPo; YouGov