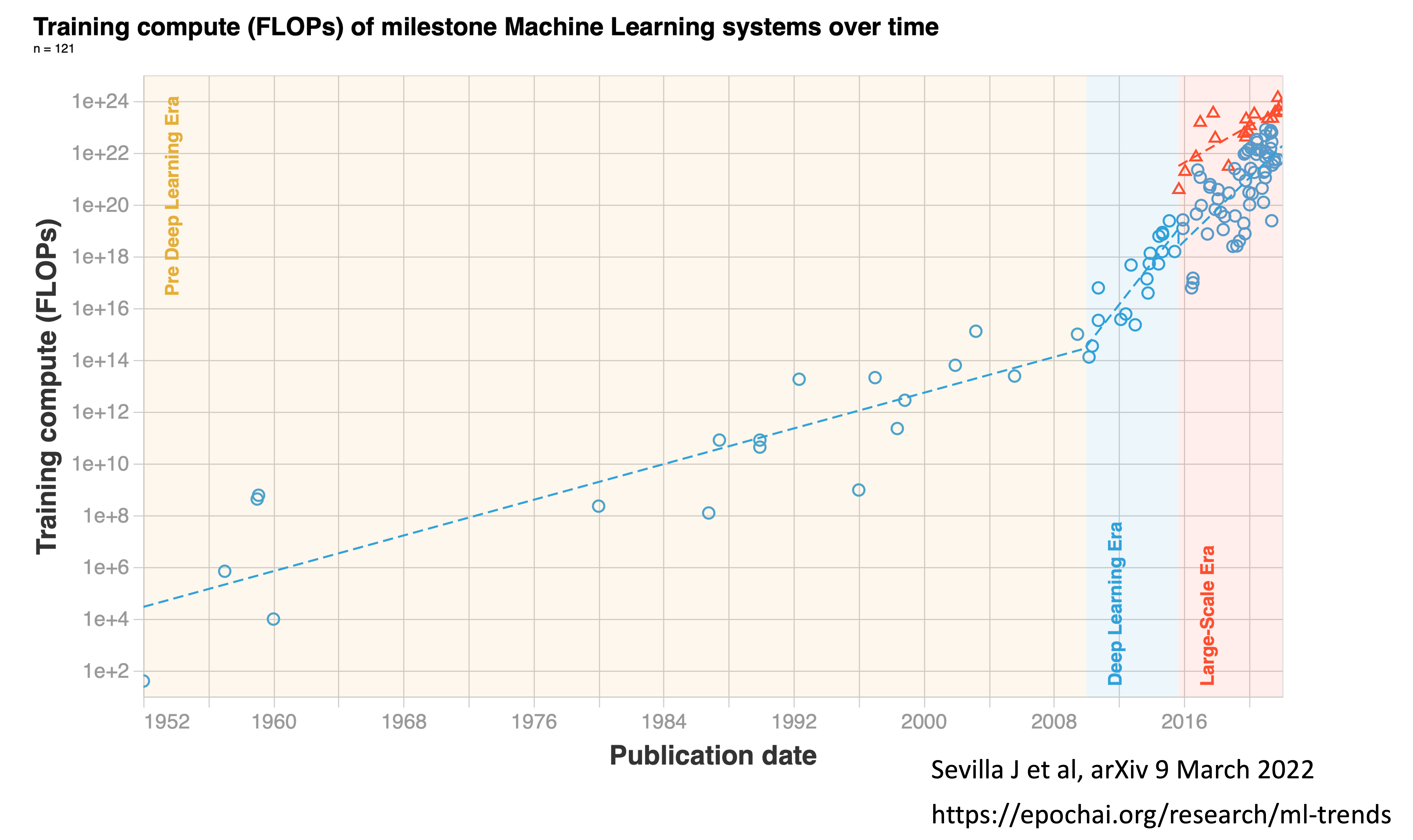
As of 2022, the training computation used has culminated with Google’s PaLM with 2.5 billion petaFLOPs and Minerva with 2.7 billion peta FLOPS. PaLM uses 540 billion parameters, the coefficient applied to the different calculations within the program. BERT, which was created in 2018, had “only” 110 million parameters, which gives you a sense of exponential growth, well seen by the log-plot below . In 2023, there are models that are 10,000 times larger, with over a trillion parameters and a British company Graphcore that aspires to build one that runs more than 500 trillion parameters.
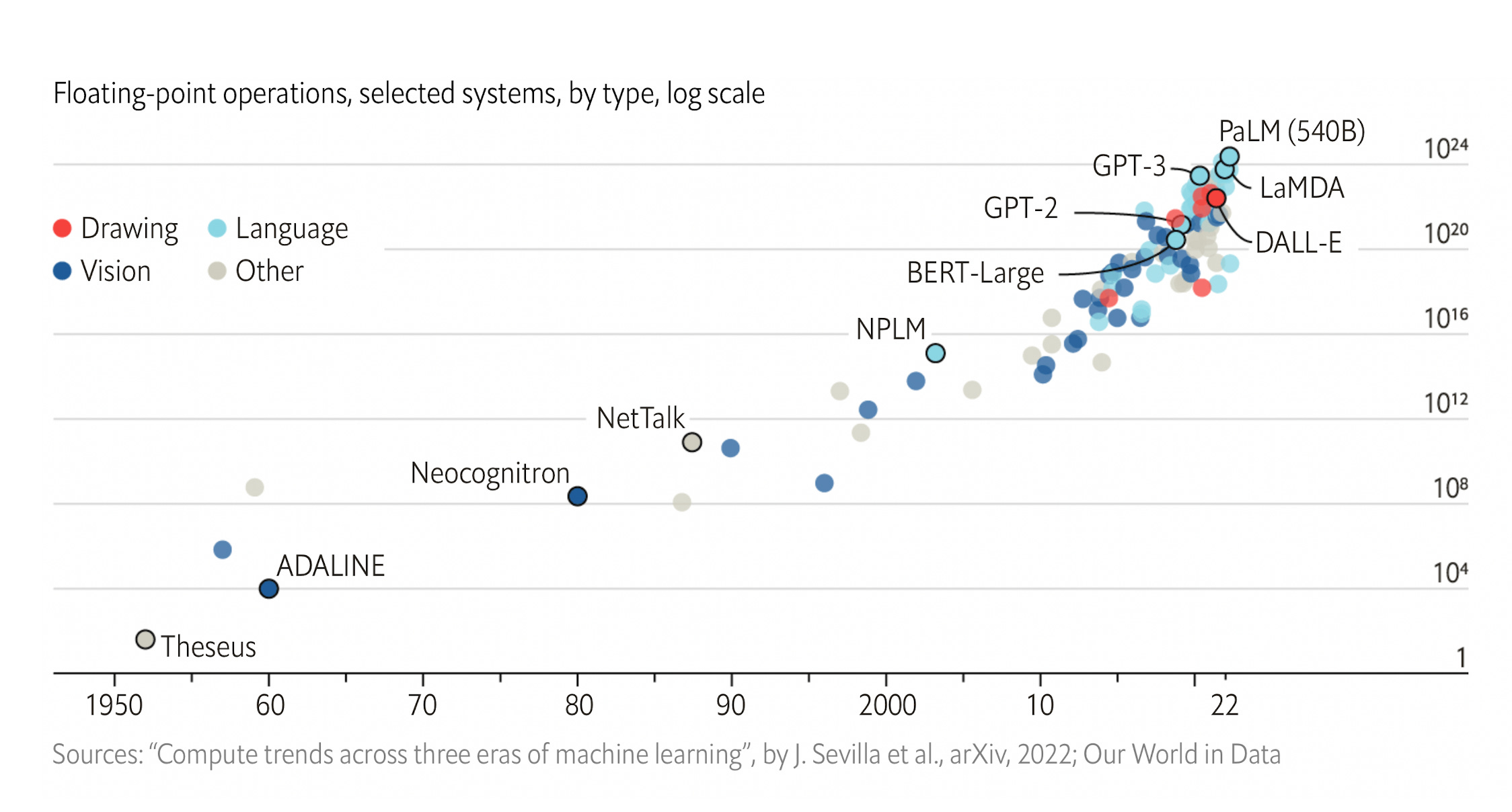
You’ve undoubtedly seen a plethora of articles in the media in recent months with these newfound capabilities from large language models, setting up the ability to go from text to images, text to video, write coherent essays, write code, generate art and films, and many other capabilities that I’ve tried to cull some of these together below. This provides a sense of seamless integration between different types and massive amounts of data. You may recall the flap about the LaMDA foundation model developed at Google—an employee believed it was sentient. (...)
The Power of Foundation Models in Medicine
Until now. the deep learning in healthcare has almost exclusively been unimodal, particularly emphasizing its applicability for all different types of medical images, from X-rays, CT and MRI scans, path slides, to skin lesions, retinal photos, and electrocardiograms. These deep neural networks for medicine have been based on supervised learning from large annotated datasets, solving one task at a time. Typically the results of a model are only valid locally, where the training and validation was performed. It all has a narrow look.
In contrast, foundation models are multimodal, based upon large amounts of unlabeled, diverse data with self-supervised and transfer learning. (For an in-depth review of self-supervised learning, see our recent Nature BME paper). The limited pre-training requirement provides for adaptability, interactivity, expressivity, and creativity, as we’ve seen with ChatGPT, DALL-E, Stable Diffusion and many models outside of healthcare domains. These models are characterized by in-context learning: the ability to perform tasks for which they were never explicitly trained.
Accordingly, going forward, foundation models for medicine provide the potential for a diverse, integration of medical data that includes electronic health records, images, lab values, biologic layers such as the genome and gut microbiome, and social determinants of health. (...)
I should point out that it’s not exactly a clear or rapid path because there is a paucity of large or even massive medical datasets, and the computing power required to run these models is expensive and not widely available. But the opportunity to get to machine-powered, advanced medical reasoning skills, that would come in handy (an understatement) with so many tasks in medical research (above Figure), and patient care, such as generating high-quality reports and notes, providing clinical decision support for doctors or patients, synthesizing all of a patient’s data from multiple sources, dealing with payors for pre-authorization, and so many routine and often burdensome tasks, is more than alluring.
by Eric Topol, Ground Truths | Read more:
Images: Sevilla J. et al, arXiv 9 March 2022
[ed. PetaFLOPS. Billions of petaFLOPS. Way back in the dark ages of 2007, the fastest computer at that time IBM's Blue Gene, apparently maxed out at a half-petaFLOP. By the way, Microsoft - not to be left out of the AI race - recently unveiled its own conversational AI tool - Bard, similar to ChatGPT (Vox). See also: Multimodal biomedical AI (Nature Medicine).]